この記事はElm Advent Calendar 2020の8日目の記事です
今年の春頃からコツコツと個人開発のアプリケーションで使うためのElm用Firestoreライブラリのパッケージを作っていたので、その紹介をします。
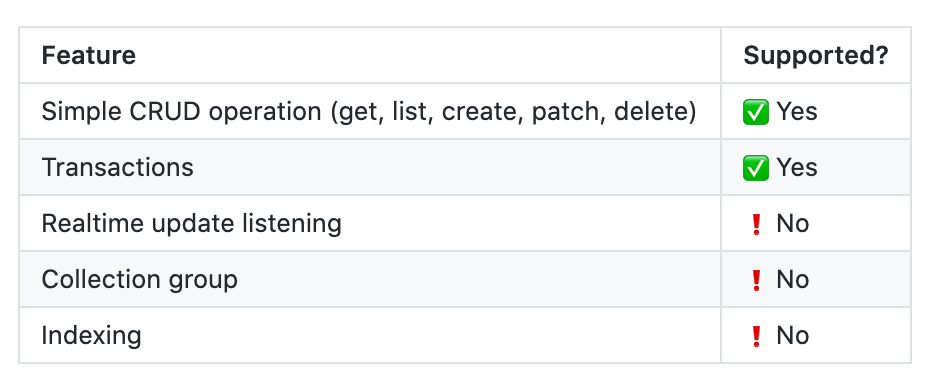
できることはREADMEに書いてあるとおりで、基本的なCRUDオペレーションが一通りサポートされているのと、たぶんトランザクションもかけられます。
また、このelm-firestoreは独自のエンコーダ/デコーダをパッケージのモジュールとして提供しており、Firestoreとの通信で使用される特別なJSONのデータ構造をパッケージの利用者が意識しなくてもよい作りになっています。
READMEにおいて "A type-safe Firestore integration for Elm." と謳っているのは、JSを書かずにFirestoreとの連携が実装でき、さらにエンコーダ/デコーダでも型安全性が担保されているという理由からです。
使い方
さて、実際のコードの雰囲気を見ていきます。
elm-firestoreでは取得されたデータは Firestore.Document というレコードで取り出せるので、それを格納できるようにしておきます。
また、Firestoreで利用可能な特別な型として Reference と Geopoint がサポートされています。
import Firestore import Firestore.Types.Geopoint as Geopoint import Firestore.Types.Reference as Reference -- model type alias Model = { firestore : Firestore.Firestore , document : Maybe (Firestore.Document Document) } type alias Document = { timestamp : Time.Posix , geopoint : Geopoint.Geopoint , reference : Reference.Reference , integer : Int , string : String , list : List String , map : Dict.Dict String String , boolean : Bool , nullable : Maybe String }
Firestore 型の生成は初期化は次のように行います。
もしもFirebase Authorizationを利用している場合には withAuthorization 関数を用いて認証トークンを与えることができます。
その他にも withDatabase 関数などでデフォルト意外のデータベースを指定したりすることもできますが、これらはoptionalです。
import Firestore import Firestore.Config as Config init: Firestore.Firestore init = let config = Config.new { apiKey = "your-own-api-key" , project = "your-firestore-app" } |> Config.withDatabase "your-own-database" -- optional |> Config.withAuthorization "your-own-auth-token" -- optional in config |> Firestore.init |> Firestore.withCollection "documents" -- optional
ドキュメントの取得は非常にシンプルで、次のように書くだけです。
取得先のパスは withCollection 関数を使って事前にセットしておきます。
fetchDocument : Firestore.Firestore -> Cmd Msg fetchDocument firestore = firestore |> Firestore.get decoder |> Task.attempt GotDocument -- GotDocument (Result Firestore.Error (Firestore.Document Document))
get 関数はデコーダを受け取りますが、このデコーダは Firestore.Decode モジュールが提供する関数群で組み立てていきます。
エンコーダのほうも、同様にパッケージから提供されている Firestore.Encode を用いて組み立てていく形になります。
import Firestore import Firestore.Decode as FSDecode decoder : FSDecode.Decoder Document decoder = FSDecode.document Document |> FSDecode.required "timestamp" FSDecode.timestamp |> FSDecode.required "geopoint" FSDecode.geopoint |> FSDecode.required "reference" FSDecode.reference |> FSDecode.required "integer" FSDecode.int |> FSDecode.required "string" FSDecode.string |> FSDecode.required "list" (FSDecode.list FSDecode.string) |> FSDecode.required "map" (FSDecode.dict FSDecode.string) |> FSDecode.required "boolean" FSDecode.bool |> FSDecode.required "nullable" (FSDecode.maybe FSDecode.string)
基本的に、Elmにおいては対象となるひとつのデータ構造に対してエンコーダとデコーダを実装することになりますが、それはelm-firestoreでも同じです。
しかし、この手間を省くことができるようにelm-firestoreでは Firestore.Codec としてCodecモジュールが導入されています。Codecを使うことでひとつの実装からエンコーダをデコーダを作ることができるので、基本的にはそれぞれ個別に定義するよりも、こちらを使うほうが楽ちんなのでおすすめです。
コーデックとはなんぞや?という方はこちらの記事をどうぞ。 izumisy.work
他にもドキュメントの作成、更新(patch, upsert)やトランザクションなど諸々ありますが、このあたりは応用的な話になるので説明を端折ります。詳しい使い方などはパッケージのドキュメントにサンプルコードとともに書かれていますので、ぜひ読んでみてください。 package.elm-lang.org
ある程度の機能は揃っていますが、まだまだ色んな機能の追加を画策中ですので将来的にダイナミックにメジャーバージョンで破壊的変更が入る可能性があります。ここだけ留意しておいてもらえれば幸いです。
リアルタイム・アップデートについて
こんだけ宣伝しといてアレですが、ひとつ決定的に惜しい点としてこのパッケージはFirestoreの一番の強みであろうリアルタイム・アップデートがサポートされていません。
これは内部的にHTTPのRESTful APIでFirestoreと通信をしているのが原因で、どうやら公式のJS製FirestoreライブラリとかはgRPCプロトコルを用いてFirestoreと通信をしているみたいです。詳細なことは僕には分かりませんがServer Streaming RPC的なのを使わないとドキュメントの更新はリッスンできないようです。少なくともRESTful APIでは100%できません。
というわけで普通にCRUDするには十分ですが、リアルタイム・アップデートを使うにはまだまだ、という感じです。いずれgRPCプロトコルでFirestoreと通信するように書き換えたいなと思っていますが、現状時間がなくてあまり手がつけられてません。
もし「やってやってもいいぜ」という方がいましたらぜひPRをお待ちしています
もちろん、バグ報告issueなども大歓迎です🙌
![実践Rust入門 [言語仕様から開発手法まで]](https://m.media-amazon.com/images/I/51t+hDKJOvL.jpg "実践Rust入門 [言語仕様から開発手法まで]")



