リポジトリにはREADMEどころか何も書かれていないのでメモしておく
# ビルドに必要なパッケージをインストール $ sudo apt install autoconf libtool # リポジトリをクローン $ git clone git@github.com:mstorsjo/fdk-aac.git # ビルド $ cd fdk-aac $ bash autogen.sh $ ./configure --prefix=`pwd`/objs $ make $ make install
リポジトリにはREADMEどころか何も書かれていないのでメモしておく
# ビルドに必要なパッケージをインストール $ sudo apt install autoconf libtool # リポジトリをクローン $ git clone git@github.com:mstorsjo/fdk-aac.git # ビルド $ cd fdk-aac $ bash autogen.sh $ ./configure --prefix=`pwd`/objs $ make $ make install
名称が分からないが、実際の例で言うとcloudspannerecosystem/yoにあるこういうやつ。
// YOLog provides the log func used by generated queries. var YOLog = func(context.Context, string, ...interface{}) {}
これだけ見ると何のために定義されているか分からない。ではなんなのかと言うと、これは後から動的に実装を差し込むために用意されているインターフェイス的なやつらしい。
親しいコードを用意すると以下のよう感じ。
package main import ( "fmt" ) // ロガーのインターフェイス var Log = func(string) {} func main() { // LogAの実装に差し替え Log = func(msg string) { fmt.Printf("LogA: %s\n", msg) } Log("Hello World") // LogA: Hello World // LogBの実装に差し替え Log = func(msg string) { fmt.Printf("LogB: %s\n", msg) } Log("Hello World") // LogB: Hello World }
Log自体には定義の段階では実装は空だが、それが呼び出されるタイミング(あるいはどこかの初期化のタイミング)で実装を差し込むことで好きな振る舞いを与えられる。普段からImmutableな雰囲気のコードばっかり書いているとこういうmutableな手法はなかなか思いつかないが、こういうのがGoっぽいのかもしれない。
今回の例は変数の型が関数だからいいが、これが構造体のポインタとかになると複雑なアプリケーションではいつ実装が差し込まれるのか分からずSEGVしてしまい危険。絶妙なタイミングで発生するランタイムエラーなバグを埋め込む可能性がある。なので、当然といえば当然だが、意図的に定義と同時に空の実装を与えたり未初期化のときに呼び出されたらエラーログを吐くなどの実装をしておいたほうが無難だろうなとは思う。
うちのコンサルが「システムアーキテクチャを決めるためには、ビジネスアーキテクチャを先に固めることが必要」と言ったら、お客様が「事業構造の変化が激しすぎてビジネスアーキテクチャを固めることが難しい」と仰った。
— ボム / SIer (@bombombomb2017) 2021年8月29日
そうだよなぁ。システムの寿命よりビジネスの寿命のほうが短くなってるのかも
これにめちゃくちゃ共感した。
よくあるアーキテクチャ設計では、ドメイン層と応用層を分離することで応用層におけるコントロール不能な変化をドメイン層に及ばないようにさせたりする。しかし、現実のプロダクト開発ではDBやフレームワークなどの応用層で起きる変化よりもドメイン層の変化のほうが圧倒的に多い。システムにおけるすべての中心にあり、あらゆるところから依存されているドメインが頻繁に変化するとなると非常にツライ。
とはいえ、ビジネス・アーキテクチャが定まっていない領域のアプリケーションほど短いスパンで頻繁なドメインの変化を求められることはむしろ必然で、ドメインを柔軟に変化させ差別化することで競合優位性を確保せねばならない。そのようなケースで設計方針などの開発都合によりドメインを変化させきれない製品のほうこそが市場競争から脱落していく。ドメインの変化に耐えることを第一にして設計せず、ただ単に教科書的な永続化装置との切り離しなどを目的視して重厚に設計されたアプリケーション基盤は、一見教科書的には正しく見えるだけに、目に見えない形で生産効率の足を引っ張ってくる。
では「コアとなるドメインがコロコロ変わるならそもそも丁寧にモデリングをすることすら意味がないのか」というとそんなことはなく、前提としてコアが変わることを念頭に置いてシステムを設計*1をすればいい。しかし見通しの立たない未来の変化に対して過度に汎化しすぎると、今度はドメインの表現力を失ってしまう。こうなると、唯一の対処法はビジネス・ドメインの変化の速さに追従するレベルで頻繁にドメインの分析とコードへの反映を地道にやっていくしかない。
これを実現するためには早い段階で頻繁にリファクタリングをしていく必要があるし、頻繁にリファクタリングをするためにはデリバリのスループットを止めないために効率のいい自動テストも必要になる。しかし、実際にはリファクタリングばかりをやっているわけにはいかないし、必ずしもテストが最初から潤沢に用意されていないこともある。そして、そういう環境が変わらないケースもある。極論、プロダクトに関わる人々が "ドメイン層の変化"という抜本的な影響の及ぶ開発コストに対してどのような態度をとるか? がシステム・アーキテクチャの在り方へ大きなインパクトを与える原因なのではないかと思う。
リファクタリングと言えば 「なぜ機能追加しないものに手をつける工数(予算)が必要なんだ云々」*2 という話は往々にして起きがちで、システム・アーキテクチャの形をいびつにさせる大きな原因は技術力ではなくむしろ社会学的/経済学的なボトルネックに集約されるだろう。大抵、こういう現象はプロダクトに対して市場規模・ビジネスモデルの都合上金回りが悪かったり、顧客とのパワーバランスからくる短期的な価値提供(機能開発)を強いられたりする場合に起きる。
個人的な体感では、toBなビジネスにおいては"対象とする顧客の業界属性"や"導入ニーズに対するパワーバランスのコントロール"がシステム・アーキテクチャの形を決める大きな鍵のような気がしている。もしも、あらゆる顧客の要望をすべて受け入れるイエスマンになってしまえば受注こそ楽かもしれないが、あっという間にカオスなAll-in-oneソフトウェアに様変わりし、継ぎはぎのメンテナンスと機能追加で工数が無限に溶けるのは目に見えている。そんなプロダクトの作り方をしている組織がドメインの分析をしたり継続的なリファクタリングをしているとは、到底思えない。
自分が開発しているgo-cleanarchitectureの中でドメインイベントのPublisher実装としてredigoを使ったPubSubアダプタの実装を用意したが、思ったよりもredigoを使ったRedisのPubSub周りに関連する実装があまりネットに転がっていなかった。
domainsパッケージなどgo-cleanarchitecture固有の実装も絡んでいるが、それでも参考になりそうなのでアダプタの実装コードを抜粋として残しておく。
https://github.com/IzumiSy/go-cleanarchitecture/blob/master/adapters/pubsub/redis.go
package pubsub import ( "encoding/json" "fmt" "go-cleanarchitecture/domains" "go-cleanarchitecture/domains/errors" "github.com/gomodule/redigo/redis" ) // サブスクライバ実装のインターフェイス type Subscriber = func(payload []byte) error // PubSubアダプタ実装の構造体 type RedisAdapter struct { conn redis.Conn psc redis.PubSubConn subscribers map[string]Subscriber logger domains.Logger } // RedisAdapterがdomains.EventPublisherの実装を満たしているかを型チェック var _ domains.EventPublisher = RedisAdapter{} func NewRedisAdapter(logger domains.Logger) (error, RedisAdapter) { // publish用のredisコネクション pubConn, err := redis.Dial("tcp", "redis:6379") if err != nil { return err, RedisAdapter{} } // subscribe用のredisコネクション subConn, err := redis.Dial("tcp", "redis:6379") if err != nil { return err, RedisAdapter{} } return nil, RedisAdapter{ conn: pubConn, psc: redis.PubSubConn{Conn: subConn}, subscribers: map[string]Subscriber{}, logger: logger, } } // ドメインイベントをPublishする func (adapter RedisAdapter) Publish(event domains.Event) errors.Domain { eventBytes, err := json.Marshal(event) if err != nil { return errors.Postconditional(err) } _, err = adapter.conn.Do("PUBLISH", string(event.Name()), eventBytes) return errors.Postconditional(err) } // サブスクライバを登録する func (adapter RedisAdapter) RegisterSubscriber(eventName domains.EventName, subscriber func(payload []byte) error) { adapter.subscribers[string(eventName)] = subscriber } // イベントのpublishを監視するgoroutineを起動する func (adapter RedisAdapter) Listen() { var channels []string for c := range adapter.subscribers { channels = append(channels, c) } if err := adapter.psc.Subscribe(redis.Args{}.AddFlat(channels)...); err != nil { adapter.logger.Error(fmt.Sprintf("Failed to start listening: %s", err.Error())) return } for { switch n := adapter.psc.Receive().(type) { case error: adapter.logger.Error(fmt.Sprintf("Error received: %s", n.Error())) return case redis.Message: // publishされたメッセージを補足した(n.Channelに対象のチャネル文字列が入っている) subscriber, ok := adapter.subscribers[n.Channel] if ok { // 対象のサブスクライバがあればデータを渡して実行する // 本当はここでエラーが出たらリトライを実行したほうが良い(Exponential Backoffとかで) subscriber(n.Data) } case redis.Subscription: switch n.Kind { case "subscribe": // Channelがsubscribeされた adapter.logger.Info(fmt.Sprintf("%s subscribed", n.Channel)) case "unsubscribed": // Channelのsubscribeが解除された adapter.logger.Info(fmt.Sprintf("%s unsubscribed", n.Channel)) } } } }
個人的にハマったのはredigoでRedisのPubSubを利用するためにはPubslisher/Subscriberでそれぞれ個別のコネクションを用意しておかないといけないこと。
これが分からなくて数時間悩んだ。
自分はvim-fugitiveとvim-flogを使っている
Plug 'tpope/vim-fugitive' Plug 'rbong/vim-flog'
fugitiveだけでもgit logは見れるが --decorate や --graph などのコマンドを使っても色がつかないのでコミットログを見ることに関しては若干微妙。
ログを見るという単一用途に関してはvim-flogがあったほうがいい。Vimに統合されたtigのような使い心地で非常に便利だと思う。
基本的には <leader>g で関連操作ができるように統一している。
nnoremap <silent><leader>gs :Git<CR>:20wincmd_<CR> nnoremap <silent><leader>gd :vert Git diff --staged<CR> nnoremap <silent><leader>gl :vert Flogsplit<CR> nnoremap <silent><leader>gg :Git commit<CR> nnoremap <silent><leader>gw :Git commit -m "wip"<CR> nnoremap <silent><leader>ga :Git add . --verbose<CR> nnoremap <silent><leader>gp :call GitPushCurrentBranch()<CR> " Pushes commits to the branch whose name is the same as we are currently checking out on function! GitPushCurrentBranch() let branch = trim(system('git branch --show-current')) echo "Git pushing to the remote branch... (" . branch . ")" execute ":Git push origin " . branch endfunction
GitPushCurrentBranch はまあまあ便利で、いまチェックアウトしているブランチを同名のリモートブランチに対してpushできる。
<leader>gs につけている :20wincmd_<CR> はウィンドウの高さを制限するコマンド。これがないとgit statusしたときに画面の半分くらいでsplitされてしまって邪魔なので、20くらいにしている。
メルカリShopsの開発組織に関する記事が興味深かった。ソフトウェアエンジニアがフロントエンド/バックエンド関係なく開発をするというのは、たしかに開発組織の理想形だと思う。
2020年にオークランドで開催されたDeveloperWeek 2020に参加したとき、IBMのCTOによるトークの中でも開発組織に関して似たような話が出ていたのを思い出した。IBMにはスクアッドと呼ばれるチームの単位が存在し、チームリード、プロダクトオーナー、フルスタックエンジニア2名、SRE2名、そしてチーム横断で仕事をするアーキテクトとデザイナというチーム体制で開発が行われる。ソフトウェアエンジニアはサーバーサイドとフロントエンドという括りでは業務を分割しない。このようなrole-agnosticなカルチャーをガレージ・メソッドとIBMでは名付けているらしい。
事実、チームをマネジメントする立場にいるとスキルセットの偏りで意図せず開発リソースがだぶつくことはあるあるバナシだ。従業員の稼働量とそれに基づく人件費をカジュアルに調整できるならまだしも、日本ではなかなかそうはいかないというケースが多いのではないか。スキルセット的にリソースがだぶついてしまうと一時的なリファクタリングや改善系のアイテムをやったりするくらいでしか調整できない。
しかし、フルスタックエンジニアの割合が多ければリソースのダブつきは最小限にできるし、横道にそれることなくリソースの100%を本質的な価値提供に集中させられる。もちろん理想論ではあるが。
最近思うがなんとなくフルスタックと一口に言っても、ソフトウェアエンジニアにおける"フルスタック"にはサーバーサイドとしてのフルスタックと、フロントエンドとしてのフルスタックがあるような気がしている。この言い方が妥当かどうかは分からない。
サーバーサイドとしてのフルスタックとは、たとえばRailsやLaravelだったりGoのRevelなどのテンプレートエンジンを用いてフロントエンドまで一気通貫で開発ができるものがそれにあたる。
一方で、フロントエンドとしてのフルスタックとはNext.js/Nuxt.jsなどの登場に端を発し結果的にBlitz.jsやRedwoodJSなど誕生に繋がったものを指している。両者はフルスタックの思想が根本的にサーバーサイド由来のものとは異なり、フロントエンドの実装を主としてサーバーサイド実装を抽象化することで、実質的にフロントエンド開発のみでサーバー側実装も含めWebアプリケーションを完成させようとしている。
かつてSails.jsやLoopback.jsなどのサーバーサイドJSフレームワークが出たあたりでよく見た「JSがあればフロントもサーバーも開発できる!」みたいな宣伝文句が若干近いような気もするが、今思えば仮にサーバーサイドがJSで書けるとしても純朴なSPAとAPIサーバという形である限り、サーバーとの通信プロトコルの検討や、エンドポイント命名、認証基盤実装など、アプリケーションが完成するまでの道のりと考慮事項はRailsのようなフルスタックフレームワークで開発するよりも明らかに高く付く。SPAが顧客要望として本当に必要なら仕方ないが、やる場合にはこれらを背負っていくことになる。
サーバサイドなフルスタックフレームワークでは難の多かったフロントエンドの自由度を獲得する手段としてAPIサーバ+SPAの構成が生まれたものの、サーバーからフロントまでを一気通貫しないことで生まれる追加の開発工数、開発者間でのコミュニケーションコストやドキュメンテーションコストは逃れられない課題になってしまった。
Blitz.jsやRedwoodJSが実現しようとしているサーバーサイド実装の抽象化は「フロントエンド開発の自由度も維持したいがフルスタックの良さも捨てたくない」というこれまでには無い目的追及の過程で生まれた前述の課題に対するひとつの解なのではないか。どんな組織であっても企業体である限り「できるだけ少ない工数で開発したい」というのは共通の目的であるし、それを叶えるのが"フルスタック"であることに違いない。
これまではフルスタックといえばサーバーサイドが中心なイメージがあったが、クラウドネイティブなインフラの成熟やフロントエンド・フレームワークのサーバーサイド領域への進出、高性能なコンピューターリソースの普及によって、これまでにない形でパワーバランスに変化が起きているような印象がある... とはいえ、仮にフレームワークで抽象化されたとしてもサーバーサイドという領域が消えるわけではないので、見方を変えればフロントエンドエンジニアであっても結局はこれまでのフルスタックエンジニアと同じ素養を求められているような気がしなくてもない。
golangのdatabase/sqlには設計に関するドキュメントが用意されており、これが興味深い。
ドキュメント自体は非常に短い。以下のリンクでサクッと読める。
中でも個人的に印象的なのは以下の説明で、ここからgolangにおけるdatabase/sqlの設計思想が見て取れる。
* Provide a generic database API for a variety of SQL or SQL-like databases. There currently exist Go libraries for SQLite, MySQL, and Postgres, but all with a very different feel, and often a non-Go-like feel. ... * Separate out the basic implementation of a database driver (implementing the sql/driver interfaces) vs the implementation of all the user-level types and convenience methods. In a nutshell: User Code ---> sql package (concrete types) ---> sql/driver (interfaces) Database Driver -> sql (to register) + sql/driver (implement interfaces)
ざっくり言うと、golangにおけるdatabase/sqlはユーザーアプリケーションに対して一般的なSQLの操作インターフェイスのみを提供するということを示している。
翻って、database/sqlを利用するアプリケーションはそのインターフェイスを介して操作する対象のSQLデータベースがなんであるかを意識しなくてもよい。アプリケーションはdatabase/sqlインターフェイスにのみ依存している状態であり、まさにクリーンアーキテクチャなどでいうところの抽象への依存(依存性逆転)そのものだ。
ではdatabase/sqlでSQLiteやMySQLを利用するとき、実装がdatabase/sqlに依存しているかというとそんなことはない。実装(ドライバ)はdatabase/sqlとは別にdatabase/sql/driverというインターフェイスに依存している。上の抜粋でいうところの sql/driver (interfaces) がそれにあたる。
便宜的にこれをユーザ層、I/F、ドライバ層と分類してみると、以下のような依存関係になる。
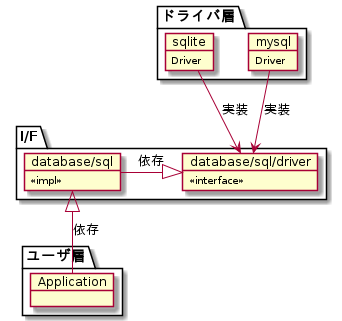
この依存関係図から、golangのdatabase/sqlパッケージは"アプリケーションでSQLを利用したいユーザー"に向けたインターフェイスを提供し、一方でsql/driverは"ドライバの実装者"に向けたインターフェイスを提供しているということが読み取れる。
利用者と実装者でI/Fを分離することのメリットは、インターフェイスを小さくかつ関心の対象を限定したものにできるというところにある。database/sqlにおいてはコネクションプーリングやセッション管理などの概念はインターフェイスに登場せず関心の対象外であり、一方でsql/driverにおいてはSessionResetterやConnectorの形で概念が登場し実装を用意することが要求される。このようにインターフェイスが分離されていることで、利用者は「database/sqlではコネクションプールやセッション管理はしなくてもいいんだな」とインターフェイスから理解でき、思考のコストが減る。
ジェネリックなSQLのインターフェイスのみを使う限りは依存のほとんどはdatabase/sqlのみに限定できる。もしRDBMS製品に固有な機能を使いたい場合には例外的にドライバから提供されているインターフェイスを直接呼び出せばいい。その場合にはドライバの実装に対する依存が生まれてしまうが、いずれにしても必要に応じて外部装置への依存性を利用者の側から選択できるようになっている点がdatabase/sqlの設計思想の優れたところなのかな、と思う。
英語の記事だが、以下の記事も同じようなことを解説している。
